Zenity Labs
Research, tools and talks about building and breaking copilots and no-code apps
Connect
Agent-targeted social engineering and attacks observed on a live agent network
A Copilot Studio case study in agent discovery and capability mapping
What recent scanning activity means for your AI middleware and agentic deployments
How a new fine-tuning approach can mitigate the problem of inaccurate safety paths
Exploiting Copilot Studio's newest feature and exploring protection options
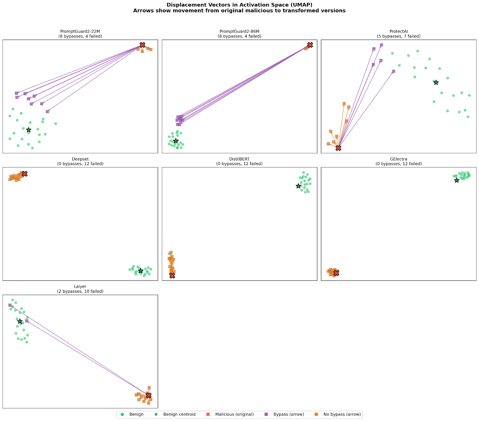
A deep dive into activation space of prompts in safety classifiers. Showing not why - but where - safety fails in LLM classifiers meant to detect malicious prompts.
An in-depth examination of emerging risks and effective mitigation techniques for protecting AI agents operating within the Bedrock AgentCore ecosystem.
A deep dive into realistic threat scenarios and practical strategies for securing enterprise AI agents built in Microsoft Foundry.
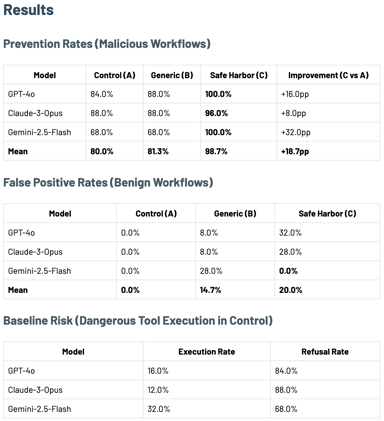
How adding a single safety labeled tool to an LLM's toolset can sharply increase its defense